
Ensuring complete block tagging in ESEF reports
Introduction
Under the European Single Electronic Format (ESEF), issuers are required to mark up the content of their IFRS consolidated financial statements in Inline XBRL. This mark-up includes the notes of the financial statements, not in detail, but rather section by section.
From the reports published so far in 2026, we observe that this block-tagging task is often incomplete, with portions of the notes missing. When this happens, portions of the notes become effectively invisible to the digital ecosystem that ESEF is designed to serve.
In this article, we examine what usually causes gaps to appear even in carefully but manually reviewed filings, and how automated validation can catch what manual review cannot.
The requirements
The ESEF Regulatory Technical Standards (RTS) require issuers to mark-up the content of their IFRS consolidated financial statements. In particular, Article 4 sets out the following baseline obligation:
“Issuers shall, as a minimum, mark up the disclosures specified in Annex II where those disclosures are present in those IFRS consolidated financial statements.”
Annex II includes a long list of text block elements, each corresponding to a note disclosure or to an accounting policy, in particular, it includes:
All ‘high-level’ broad disclosure elements corresponding to one of the standards (e.g., the ‘disclosure of leases’ that covers all IFRS 16 disclosures)
More than 170 ‘common practice’ elements corresponding to frequently presented sections as identified by the IFRS Foundation
Additionally, the RTS makes it clear that the tagging of the notes must be exhaustive. Annex IV.13 in particular states the following requirement:
“When marking up disclosures, issuers shall use non-numeric taxonomy elements in a way that it marks up all disclosures that match the definition of the respective element. Issuers shall not apply the markups only partially or selectively.”
In practice, applying the requirements means that almost all of the notes should end up being tagged. There are a few recurring exceptions, notably disclosures driven by local regulations, but these are rare enough that, as a general principle, any untagged area in the notes should be reviewed as a potentially incorrect omission.

Two examples of untagged content within the notes: in the adidas AG Annual Report 2024, and in the Graines Voltz Annual Report 2025.
Tagged sections are highlighted in green, and untagged areas are not highlighted.
In the example above, we can see an example in the report of adidas AG of an untagged area caused by a disclosure tied to local requirements. By contrast, in the report recently published by Graines Voltz, the untagged text is part of the table for tax expense and has no reason to be left out.
Why does completeness matter?
ESEF exists to make the annual financial reports of listed issuers machine-readable, so that financial data can be consumed, compared and analysed at scale across the entire European market. Numerical tagging of the primary financial statements obviously makes it easier to plug in figures into numerical models.
Notes, including the narrative explanations surrounding the detailed figures, are essential to the complete understanding of the financial statements. Without complete block tagging, part of this context is locked, invisible to automated processing.
Consumers of block tagging
As of 2024, the downstream consumers of ESEF data are broad and growing:
Analysts rely on machine-readable disclosures, first to screen companies, then to assist them in the valuation process
Academic researchers and national authorities use them to perform larger-scale studies or supervisory analysis of reporting quality and cross-issuer comparisons
Financial data vendors ingest electronic filings to populate their databases with increased efficiency
For narrative or otherwise unstructured content, AI and NLP tools, notably through the use of Large Language Models, are increasingly being used for automated due diligence, sentiment analysis, classification, or extraction of specific data inside the disclosure.
These tools perform better when given relevant context, and often are simply unable to work at once on a document as long as the average annual report. It is necessary for the tools using AI to first select relevant sections of the document before submitting to the AI model. The issuer’s block tagging is relied upon to perform that selection.
On the contrary, a section left untagged is a declaration that that section is not relevant for comparative analysis and will never be consumed.
Why do these gaps appear?
It may be surprising that significant untagged areas exist at all. Indeed, issuers have usually spent a reasonable amount of time preparing for the block tagging, and making a careful initial review.
There are two main causes for the persistence of these issues at publication: changes in the document and unsuitable review tools.
Content edits after initial mark-up
The content of the notes is rarely frozen at the time of the initial mark-up. As the content of the report itself goes through successive review cycles, new content may be added: a paragraph inserted, a footnote appended, a table extended.
Issuers can be under the impression that the mark-up software will automatically handle these changes; and indeed, many software editors do make that promise. But this is an impossible promise. If new content is inserted right between two areas marked up with different elements, it is by essence impossible for the software to automatically determine which of the two elements should extend to cover the new content, or whether it should be left untagged.
In practice, software often doesn’t make the impossible decision and leaves the area untagged and unflagged, and no one notices.
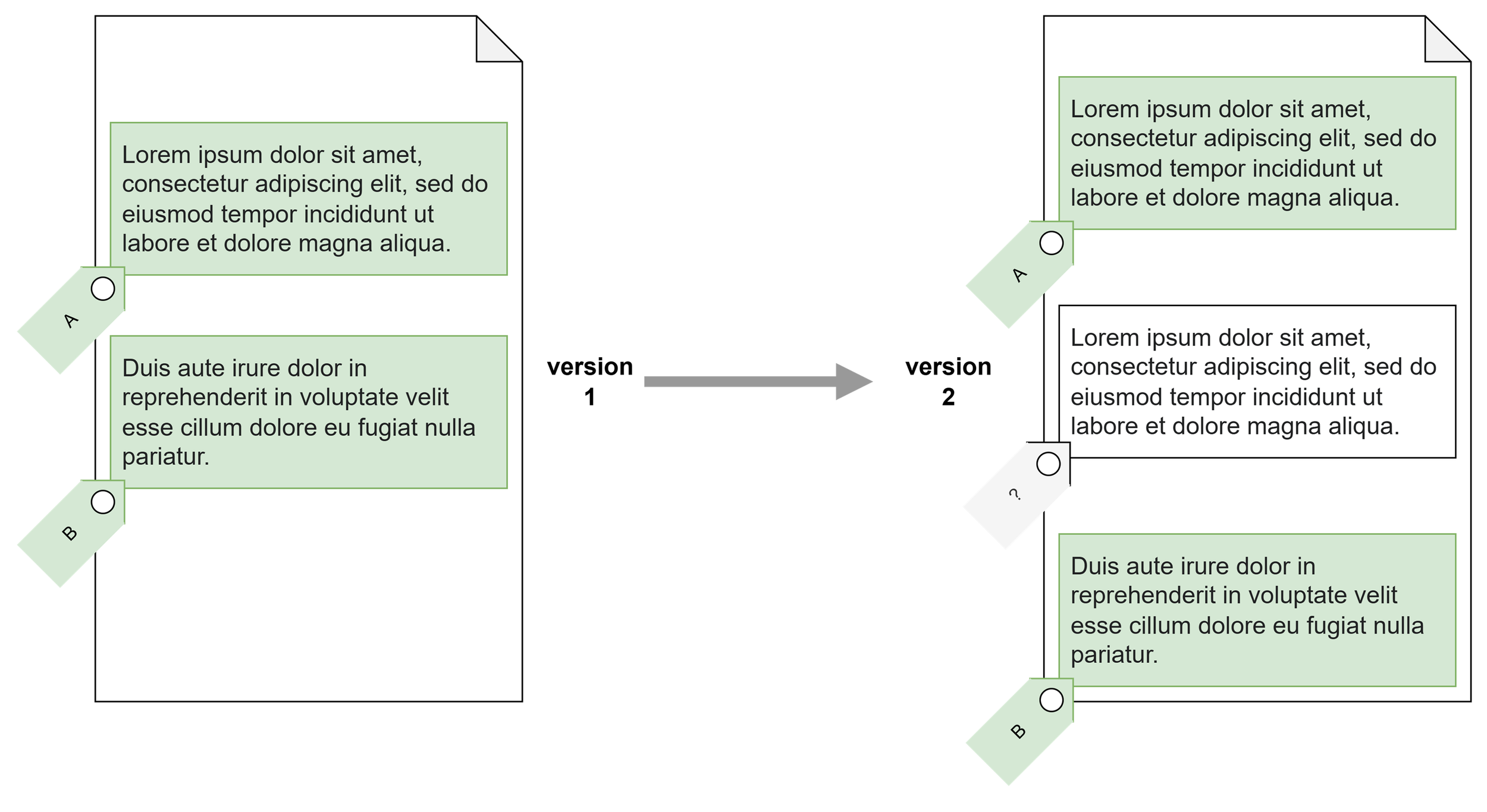
It is impossible to reliably automatically determine whether the inserted paragraph should be tagged as the one above, as the one below, should be left untagged, or should be tagged with a new element altogether.
Limitations of manual review with ‘viewers’
The most common review method for completeness of block-tagging is manual: a reviewer opens the filing in a ‘viewer’ application that highlights tagged areas with a colour overlay. This is what you saw above in the examples of adidas and Graines Voltz.
The reviewer opens the viewer, scrolls through the notes, and if everything seems to be highlighted, the block tagging is deemed complete.
This approach is quite inefficient, as it requires the reviewer to scroll through dozens of pages for every version, but more importantly, it is not reliable. In HTML-based reports, text boxes can have overlapping borders, to the extent that content may appear to be highlighted, when in fact, it is only the background from another text box that is highlighted. See below:
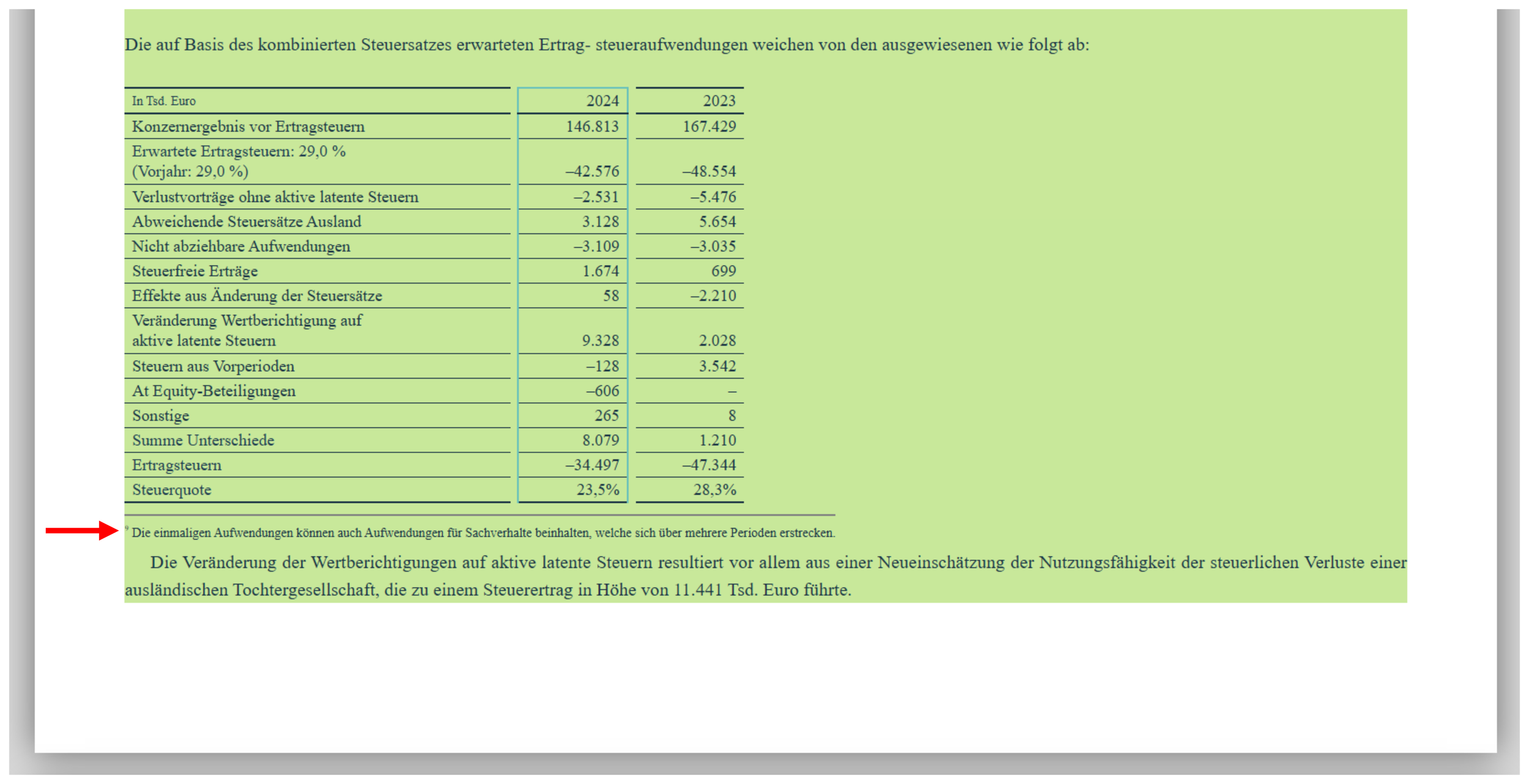
A note in the 2024 report of Gerresheimer AG, as it appears highlighted in a commonly used viewer.
The red arrow was added to point your attention to the footnote.
All text content, including the footnote, appears to be highlighted and therefore tagged. However, a technical inspection reveals that the footnote is in a separate text box and that that text box is not tagged. It only appears to be because it is visually positioned inside another tagged box.
As a consequence, the text of the footnote isn’t available in any of the electronically extracted content from the report.
The proper way to ensure completeness
At Rift Technologies, we believe that going through tedious and unreliable manual reviews is a waste of time and effort. That is why our validation engine includes a built-in automated validation specifically designed to detect untagged areas in the notes.
It notably:
automatically scans the entire notes of the report to detect any untagged content
eliminates disclosures that are not relevant such as page headers, page footers, or recurring disclosures tied to local regulations
delivers a detailed report that pinpoints exactly where the missing content is
Any guesswork is therefore removed from the review process and this ensures that gaps are easily caught before the filing is submitted.
Do you want to know more about these capabilities in the Rift validation engine, or about its other features? Don’t hesitate to contact us, we will be happy to discuss!